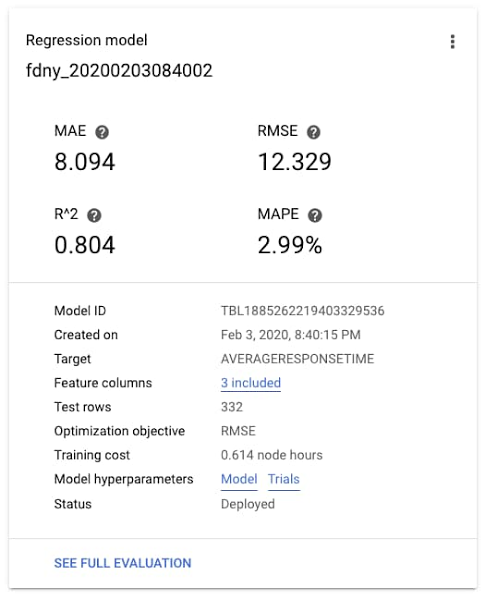
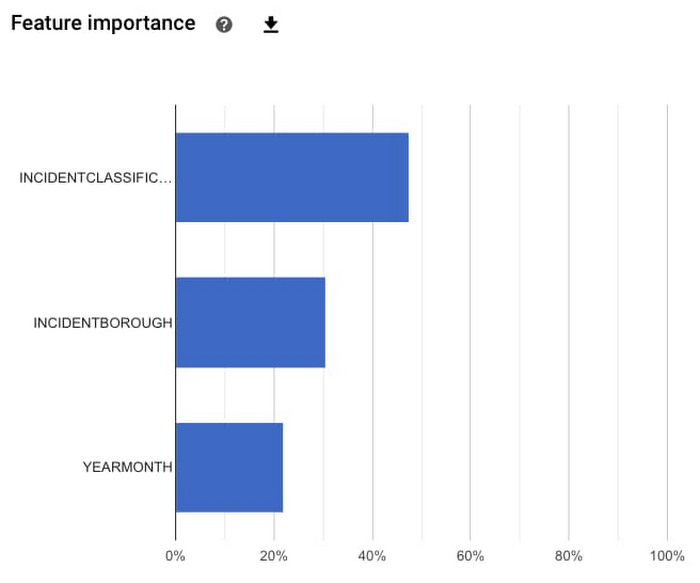
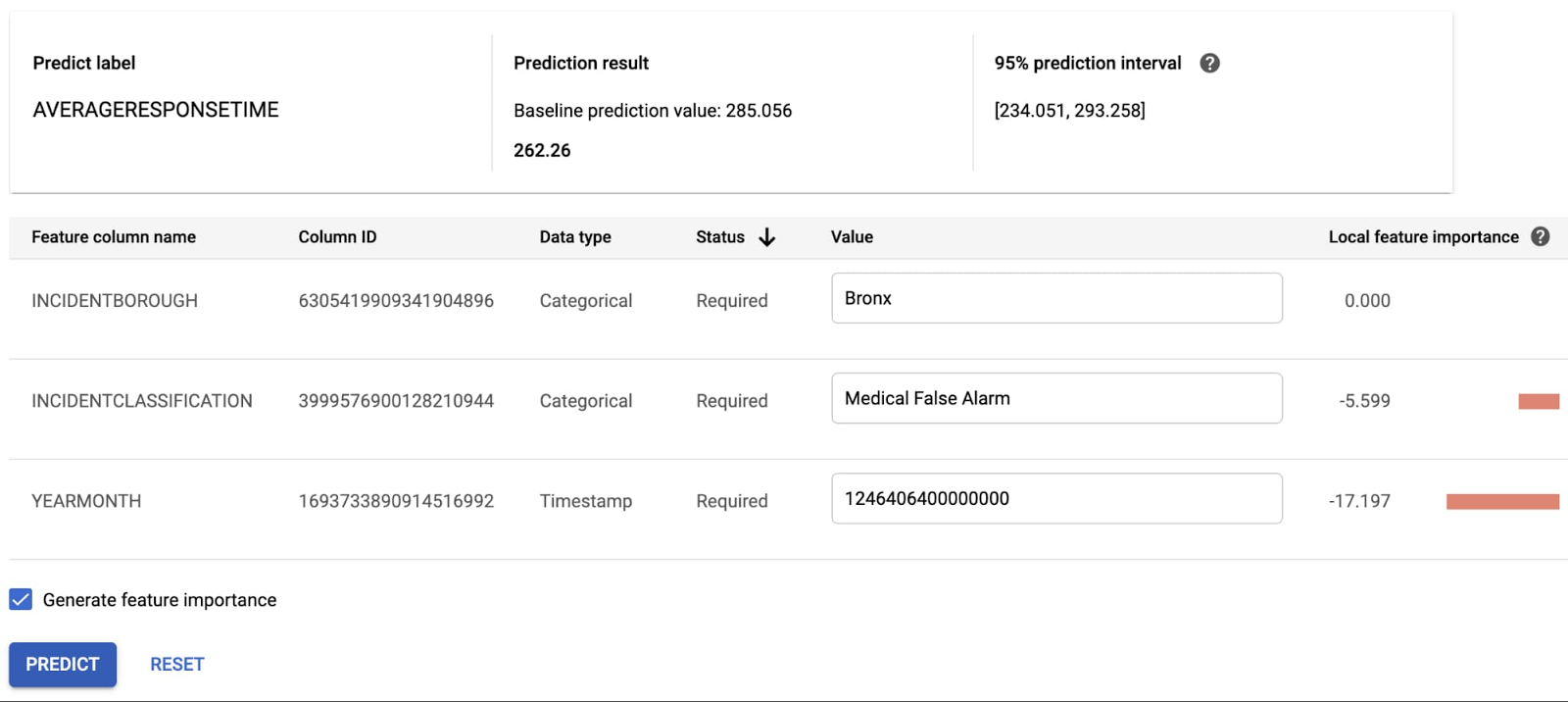
How Google Cloud is helping global governments during the COVID-19 pandemic, and our future plans to work with the public sector
We are deeply committed to providing the public sector with the best technology to help improve government services and increase operational effectiveness, and we continue to work with government agencies to advocate for and contribute to the responsible and beneficial use of technology. Around the world, government agencies are working hard to meet citizen needs and weather the impact of COVID-19, and we are proud that many of our solutions are being used as part of this critical work.
New solutions to support government agencies during COVID-19 As the COVID-19 situation continues to evolve, we’re committed to supporting our public sector customers around the world by helping them provide the services that citizens rely upon.
Internationally, we’re working with a number of governments to provide collaboration solutions and tools to track the spread of COVID-19. For example, in Spain, we’ve set up an app for the regional government in Madrid to help citizens perform self-assessments of coronavirus symptoms and offer guidance, easing the demands on the healthcare system. In Italy, the 70,000+ employees working in the Veneto region’s healthcare system are relying on G Suite to maintain their high level of service and patient care during the COVID-19 crisis. And in Australia, the Australian Government Department of Health launched its Coronavirus Australia App. Built on Google Cloud, the app offers real-time information and advice about the fast changing COVID-19 pandemic.
In Peru, the Judiciary branch is using Google Meet to continue operating during the nation-wide quarantine. Through video conferences they are carrying out both internal meetings and also hearings. By doing this, attorneys, lawyers and judiciary clerks don’t have to physically attend court, keeping the virus from spreading, while maintaining the administration of justice in the country.
And in Norway, the City of Trondheim has been using G Suite to establish strong and effective collaboration for its employees which now is more important than ever. The accumulated number of Google Meet sessions over an only 7 days period passed the 60,000 threshold while the video conferencing experience was smooth, intuitive and frictionless for all participants. Using Google Cloud instead of relying on legacy on-premises solutions for making this possible, helps the City of Trondheim to stay connected and keep each other up to date even in these difficult times. With G Suite’s Google Meet, the city can continue with political meetings relevant to the community and schools are using it to keep the classes running.
Speaking of schools, we’re supporting remote learning for public schools and universities around the world. From Italy to South Korea and the United States to South Africa, our Google Meet technology is enabling teachers to hold classes to keep kids learning. In Malaysia, where schools are closed in response to COVID-19, we’ve been hosting daily webinars for teachers, bringing them up to speed on how they can leverage Google tools to teach from home. In Italy, we worked with the Italian Ministry of Education—the governing body accountable for millions of Italian schoolchildren—to rapidly shift students entirely to remote learning. Our teams banded together, and engineers worked around the clock to speed up the enrollment process, even making a virtual help desk available for timely activation and support. As a result, the Ministry of Education was able to help bring millions of students online in a matter of days.
Our future plans to support public sector customersWe’ve significantly ramped our resources to support government agencies recently, and we are exploring new ways to support public sector customers. We believe that technology is a critical component of government services and that we can provide solutions to government agencies to help them best accomplish their mission. As our government solutions become more robust, and as we continue to gain important certifications to service important government workloads, we are leaning into expanding our engagement with the public sector.
We continue to be transparent about the work we will do in this space, and we plan to participate in a number of large upcoming RFIs and RFPs, including with the U.S. State Department and National Oceanographic and Atmospheric Administration, as well as qualifying to perform unclassified work under the recently announced Commercial Cloud Enterprise (C2E) initiative, and engaging with other government agencies around the world on a range of important projects.
We are fully committed to serving the public sector, especially at this extraordinary time, and we look forward to working with government agencies as they seek to optimize their use of cloud services to streamline and improve government operations. Read more about our work with the public sector here.